
コンテンツ
言語グリッドインドネシアオペレーションセンター運営開始
![]()
新規の言語サービス・言語資源が追加されました
![]()
電子情報通信学会「人工知能と知識処理」「異文化コラボレーション」合同研究会のご案内
![]()
言語グリッドプロジェクト紹介:YMC-Viet project
![]()
言語グリッド ユーザ紹介:CELI
![]()
定期メンテナンス:2013年1月15日・2月12日・3月12日
![]()
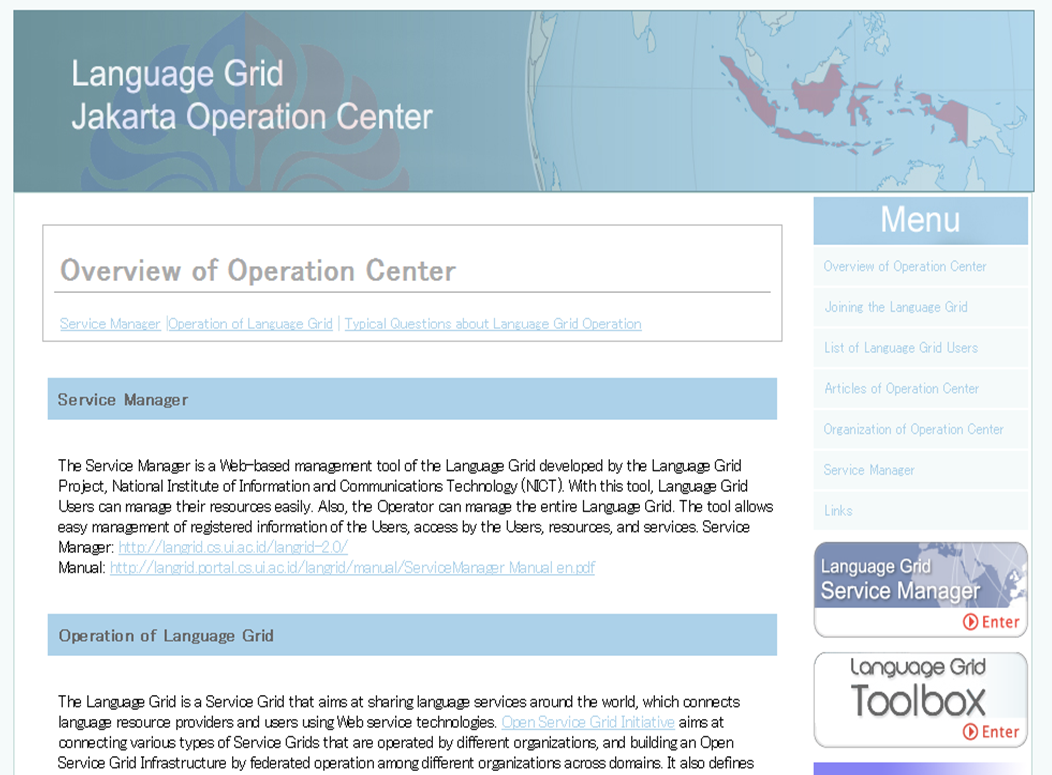
言語グリッドインドネシアオペレーションセンター運営開始
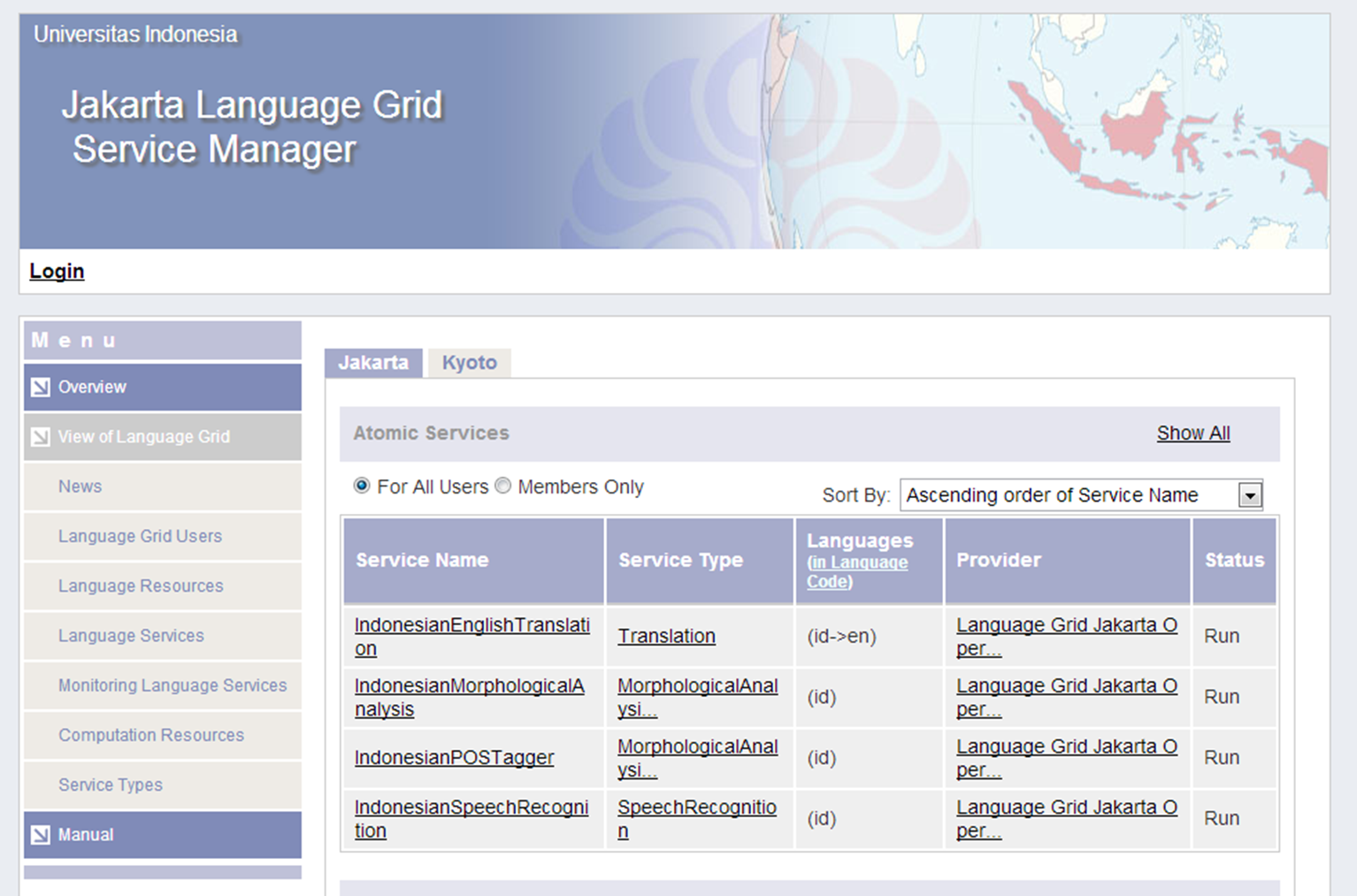
インドネシア大学情報検索研究室が言語グリッドジャカルタオペレーションセンター(http://langrid.portal.cs.ui.ac.id/langrid/)として、言語グリッドの運営を開始いたしました。本言語グリッドでは、非営利目的および研究目的での利用が許可されています。現在、インドネシア語の形態素解析や、インドネシア-英語翻訳、インドネシア語の音声認識などインドネシア大学がこれまで研究開発してきたインドネシア語の言語サービスが4種登録されています(http://langrid.cs.ui.ac.id/langrid-2.0/language-services)。今後もインドネシア語を中心に多様な言語サービスが追加されていく予定です。
既にジャカルタオペレーションセンターは連携運営組織として言語グリッド京都オペレーションセンターと覚書を締結しており、ジャカルタオペレーションセンターが運営する言語グリッドから京都オペレーションセンターの言語サービスを利用することは可能です。現時点では、京都オペレーションセンターの運営する言語グリッドからジャカルタオペレーションセンターの言語サービスを利用することはできないため、ジャカルタオペレーションセンターの全ての言語サービスをご利用になりたい場合は、ジャカルタオペレーションセンターと覚書を締結してください。 覚書締結の詳細はジャカルタオペレーションセンターの参加方法をご覧ください(http://langrid.portal.cs.ui.ac.id/langrid/procedure.html)。
![]()
言語サービス・言語資源
◆新しい言語サービスタイプが追加されました。【形態素係り受け解析器】文を形態素に分割し、係り受け関係を示すサービスです。
◆新しく17言語サービスが追加されました。 (言語サービス名、提供者(著作権者)、対応言語の順に記載しています。)
【形態素係り受け解析器】
- MaltParser、言語グリッド運営組織(Johan Hall, Jens Nilsson and Joakim Nivre)、すべての言語
- Yahoo! 日本語形態素解析、言語グリッド運営組織(Yahoo! Japan)、日本語
- Frog、言語グリッド運営組織(ILK Research Group (Tilburg University, the Netherlands) and CLiPS Research Centre (University of Antwerp, Belgium))、オランダ語
- HunPos、言語グリッド運営組織(Peter Halacsy, Andras Kornai, Csaba Oravecz)、すべての言語
- Illinois Part-of-Speech Tagger、言語グリッド運営組織(Nick Rizzolo and Dan Roth)、英語
- Kyoto Text Analysis Toolkit、言語グリッド運営組織(Graham Neubig)、日本語・中国語
- Z Part-of-Speech Tagger、言語グリッド運営組織(Yue Zhang and Stephen Clark)、英語・中国語
- Gensen Web (Euro)、言語グリッド運営組織(中川裕志、前田日明、小島寛之)、英語・スペイン語・フランス語・イタリア語・フィンランド語・スウェーデン語
- Gensen Web (Japanese)、言語グリッド運営組織(中川裕志、前田日明、小島寛之)、日本語
- Gensen Web (Chinese)、言語グリッド運営組織(中川裕志、前田日明v小島寛之)、中国語
- Yahoo!キーフレーズ抽出、言語グリッド運営組織(Yahoo!Japan)、日本語
- Japanese Summarizer、言語グリッド運営組織(大沢和宏)、日本語
- Open Text Summarizer、言語グリッド運営組織(Nadav Rotem)、英語・ドイツ語・スペイン語・ロシア語・ヘブライ語・エスペラント語
- Yahoo! 係り受け解析、言語グリッド運営組織(Yahoo!Japan)、日本語
- Z Parser、言語グリッド運営組織(Yue Zhang and Stephen Clar)、中国語
- NExT、言語グリッド運営組織(三重大学、立命館大学)、日本語
- Open Jtalk、言語グリッド運営組織(名古屋工業大学情報工学科)、日本語
![]()
電子情報通信学会「人工知能と知識処理」「異文化コラボレーション」合同研究会のご案内
下記のとおり電子情報通信学会「人工知能と知識処理」「異文化コラボレーション」合同研究会が開催されます。
(論文募集は終了しています)
【日程】2013年2月18日(月)
【場所】大阪電気通信大学 寝屋川駅前キャンパス
【テーマ】言語グリッドと異文化コラボレーション
![]()
言語グリッドプロジェクト紹介:YMC-Viet project

(YMCViet児童研修にて)

(YMCViet児童研修にて)
NPO法人パンゲアでは、2010年度にベトナムで児童を介して多言語間で知識伝達するYMCモデル(Youth Mediated Communication Model)による新興国支援モデル実証「YMCVietプロジェクト」を行いました。歴史的な背景や生活習慣の背景などから、文字の読み書きに問題のある農民が特に農村部では多い現状があります。各地の農業普及センターなどでの農業支援の講習会などに参加しても非識字の問題がネックでわからないのが嫌だからと、なかなか正しい農業知識の伝達ができていません。半数以上の農民が正しい知識を持たず、農業をしていることで、収益・環境など様々な面で問題を抱えています。
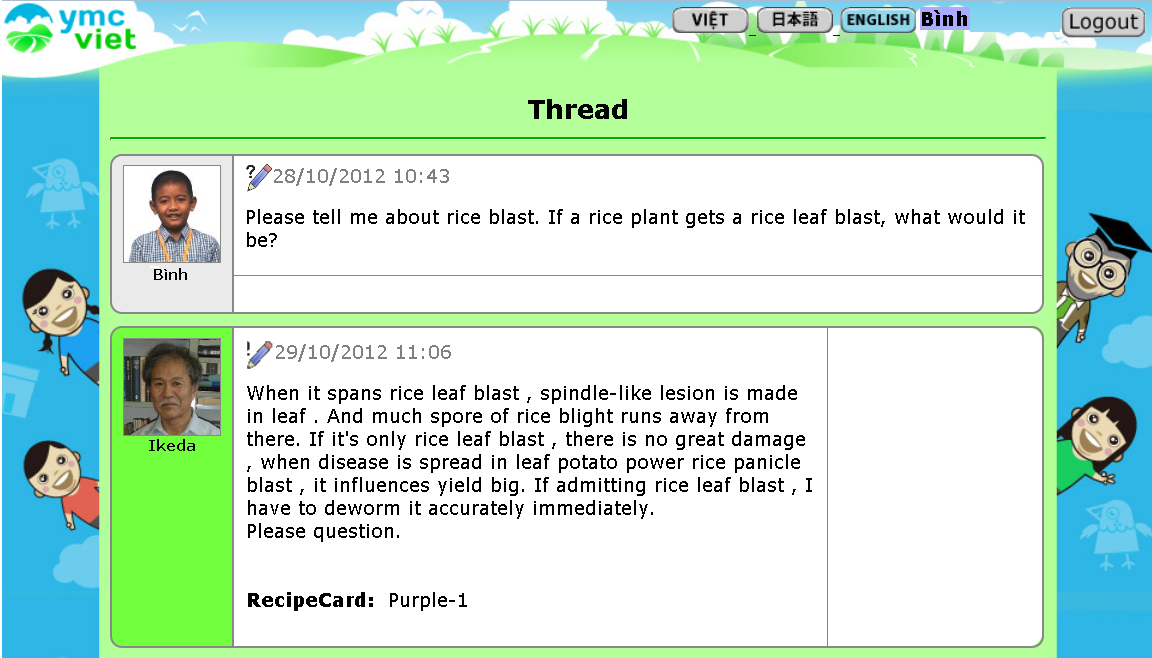
YMCVietプロジェクトでは、児童がセンターに週一回きて、週二回親のたんぼに観察に行き、毎日温度や湿度を計測します。たんぼでは葉の高さや葉の色を観察し、害虫や稲の病気を携帯電話でとります。また子供達は、パンゲアが開発したYMCシステムを利用して、楽しい農業画面から農業に関する質問を投稿します。日本の農業専門家チームはそれらのデータを見て、子供の質問に答えてくれます。子供達も農業知識を習得し、それらを家に帰って親に伝えてくれるのです。言葉の壁は、言語グリッドによる機械翻訳や用例対訳、そして人力による翻訳修正で乗り越えます。毎回センター訪問後に帰宅した子供達は、平均15分間程度、親に説明してくれていました。当時のプロジェクトの詳細は「言語グリッドニュースレターNo.28号」を参照ください。
前回は短期間であるものの、このYMCモデルがうまく稼動できるかを見ました。自分の農業という職業にこれまでなんの関心も示さなかった子供が、たんぼに足を運び、親になにか困ったことはないか聞いてくれて、その解決策を専門家から持ち帰ってくれるこの取り組みは、実は親子の絆が間違いなく深まっていることがわかっています。ベトナムの中央政府も地方政府も、今後のさらなる展開に期待を寄せてくれています。ベトナム政府のNguyen Chien氏(ベトナム農業開発省 統計情報センター長)は、前回のプロジェクト記者発表会で「ベトナムの100万人以上の農民がYMCプロジェクトを必要としている」と発言し、会場を沸かせました。一方で、この活動から様々な課題が見えてきました。例えば、専門家による回答の機械翻訳結果を人力修正によりベトナム語に翻訳される過程の人的作業負荷、児童から報告される田んぼの環境情報の解釈方法、日本の専門家と現地の専門家との間での農業知識共有など、分野が多岐に渡っています。
今回、こういった課題を整理した上で第2期目となるYMCVietプロジェクトを前回と同じフィールドであるベトナム・メコンデルタ流域で始めました。参加児童は15名と前回の半分ですが、前回で見えた課題の中で、特に日本の専門家とベトナムの児童をつなげるコミュニケーションの改良に対し、改善案を試みています。原則として毎週日曜日の午前中にYMC Vietのセンターへ、児童が毎回参加してくれています。そして現地スタッフから毎回活動報告が送られてきます。ここにはこれまで7年間パンゲアが培ってきた多言語掲示板(言語グリッドToolbox)が京大等の協力によって進化して使用されています。全く英語は話せない現地スタッフと私達が毎週これを見ながら、現地での問題解決を図るためコミュニケーションしています。
本プロジェクトに関わっている研究者の方々は、児童を介してコミュニティに情報を伝達していくYMCモデルのフィールドに対して、各分野から研究の可能性を見出してくださっており、サービスサイエンスの観点や、農業情報の観点や、社会学の観点などから、YMCモデルに関する既に研究論文や学会発表などが出始めています。将来的に「ベトナムの100万人以上の農民」だけでなくYMCを必要とする地域に対しサービス提供できるように、パンゲアでは学術分野の方々と連携して本フィールドを改善しながら運営していきます!
(2012年11月 NPOパンゲア 高崎俊之)

![]()
言語グリッド ユーザ紹介(第31回):欧州初の言語グリッド「Linguagrid」

CELI was established in 1999 in Turin, Italy by a group of language technology researchers with the aim to address the growing market in language engineering. Today, CELI is a provider of software solutions in the field of Natural Language Processing (NLP) in mono-, multi-, and cross-language perspective. With 36 employees and collaborators, CELI operates in Turin, Italy and, since 2006, in Grenoble, France.
In 2010 CELI has put online a European Node of Language Grid, Linguagrid (http://www.linguagrid.org/). Linguagrid hosts family of Web services developed, published and maintained by CELI, which is open to the private and public institutions. Services available in Linguagrid include ISO certified services, services of Language Grid standardized format (Morpho Analysis - MAF, Language Identification, Dictionary Translation), community recognized services (Text Classification, Text Clustering), and CELI developed services (Dependency Parsing, Sentiment Analysis).
One of the new and captivating services available in Linguagrid are domain-adaptable, corpus-based linguistic services on a standard LRaaS infrastructure. A corpus ingestion service (implemented as a Web Application) allows users to upload corpora of documents and then generate a web accessible corpus from them. A given search query can be used for filtering the documents from the original corpus. The filtered resources can be used by the corpus-based services as a Dynamic Corpus during the process of model generation. This feature allows to fully exploit the expressive power of SOLR search engine (i.e. faceted browsing, proximity search, wildcard queries) for domain adaptation. By leveraging the presence of a search engine as intermediate layer, this approach enables the full reuse of corpora for different applications (classification clustering etc.), since distinct models can be generated starting from the same corpus.
(November 2012, Milen Kouylekov, CELI, Turin, Italy)
![]()
定期メンテナンス: 2013年1月・2月・3月
下記の通り予定しております。この日時に言語グリッド利用の予定がある場合は、事前にoperation [at] langrid.orgまでご連絡ください。
- 1月15日(火)10:00-13:00 (JST)
- 2月12日(火)10:00-13:00 (JST)
- 3月12日(火)10:00-13:00 (JST)
【注意】毎月第一月曜日に行っておりましたが、毎月第二火曜日10:00-13:00 (JST)に変更致します。
言語グリッドのポータルサイトのWhat's newにも掲載いたしますので、こちらhttp://langrid.org/jp/をご覧ください。
![]()